Text2FX: Harnessing CLAP Embeddings for Text-Guided Audio Effects
Annie Chu, Patrick O'Reilly, Julia Barnett, Bryan Pardo
Northwestern University
Abstract
tl;dr: How can we apply audio effects (e.g., EQ, reverb, etc) with any natural language prompt (e.g., make this ‘warm and cozy’)?
This work introduces Text2FX, a method that leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., “make this sound in-your-face and bold”). Text2FX operates without retraining any models, relying instead on single-instance optimization within the existing embedding space. We show that CLAP encodes valuable information for controlling audio effects and propose two optimization approaches using CLAP to map text to audio effect parameters. While we demonstrate with CLAP, this approach is applicable to any shared text-audio embedding space. Similarly, while we demonstrate with equalization and reverberation, any differentiable audio effect may be controlled. We conduct a listener study with diverse text prompts and source audio to evaluate the quality and alignment of these methods with human perception.
Examples
| Target Word | FX | Sample | Clean Audio | FX’d Audio |
|---|---|---|---|---|
| bright | EQ | Music | ||
| coming through an old telephone | EQ | Speech | ||
| underwater | Reverb | Music | ||
| hollow and far away | Reverb | Speech | ||
| dramatic | EQ –> Reverb | Music | ||
| warm and full-bodied | EQ –> Reverb | Speech |
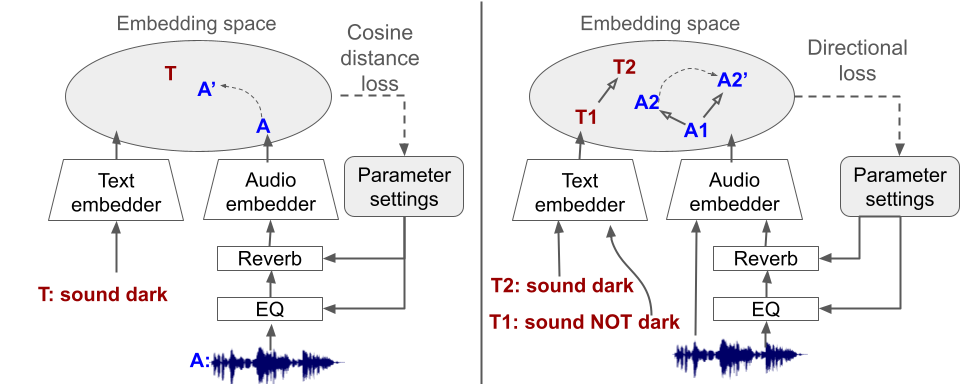
How do we optimize?
Overview
We employ single-instance optimization (also referenced as inference-time optimization) – directly optimizing in the FX parameter space, bypassing audio space to avoid introducing unwanted artifacts. We try two different approaches for text-audio optimization of CLAP embeddings:
- Text2FX-cosine (left): directly minimizes the cosine distance between the optimized audio embedding and the target text embedding
-
Text2FX-directional (right): leverages the directional relationship between two text-audio embedding pairs, guiding the optimized audio embedding to move in the direction defined by the difference between the target text and a contrasting text prompt.
Example Optimization (Ex.1)
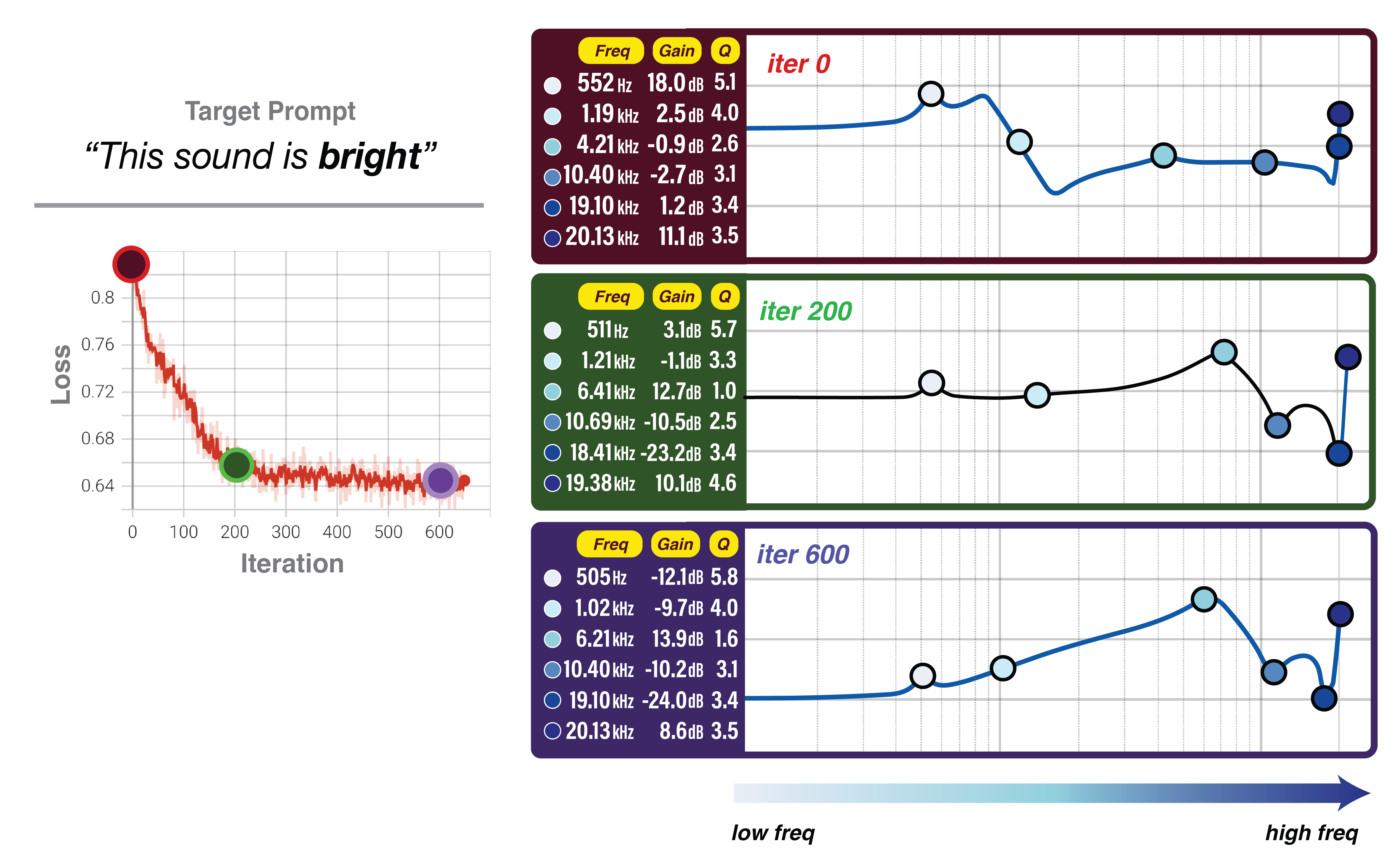
| Iteration 0 (randomly applied FX) | |
| Iteration 200 (mid-optimization) | |
| Iteration 600 (end) |